


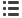













 54 / 84
54 / 84


EMBEDDED
59 • FEBBRAIO • 2016
HARDWARE
|
FPGA VERSUS GPU
54
ma di prodotti. A differenza di un tradizionale
GPU, la FPGA non esegue il codice. In sostanza,
un FPGA è equivalente ad un chip di silicio che
è stato appositamente realizzato per un compito
molto specifico.
Le GPU sono costituite da una o più unità di
elaborazione (CU) e ogni CU è costituito da una
matrice di elementi di elaborazione (PE). La ge-
rarchia di memoria della GPU è costituita da cin-
que tipi: private, constant, local, image e global.
Le GPU possono essere programmate attraverso
OpenCL, che è un framework standard aperto
per la programmazione di una serie di disposi-
tivi, tra cui CPU, APU (cioè, Accelerated Proces-
sing unità) e
IntelXeon Phi.
L’attività di crittografia e decrittografia viene
eseguita su schede grafiche utilizzano linguag-
gi di programmazione software come CUDA e
OpenCL.
Le schede grafiche di oggi sono abbastanza veloci
e l’esecuzione di programmi sulla GPU possono
accelerare notevolmente le attività che coinvol-
gono grandi quantità di dati e processi altamente
paralleli. Schede Tesla di
Nvidiasono un buon
esempio della velocità della GPU, dove un paio di
schede grafiche possono essere utilizzate al po-
sto di un piccolo gruppo di CPU (in genere per
le simulazioni e attività di modellazione). Le ul-
time generazioni di GPU sviluppate, uniscono
prestazioni elevate a una migliorata efficienza
energetica. I linguaggi per programmare su GPU
richiedono tecniche appositamente realizzate per
il gpu computing. Inoltre, ogni soluzione neces-
sita di una serie di tecnologie aggiuntive come
sistemi di raffreddamento che possono influire
sia sul costo che sulle prestazioni del sistema. At-
tualmente le performance offerte dalle GPU sono
in crescita e le piattaforme grafiche stanno occu-
pando una fetta di mercato sempre più rilevante
nel calcolo ad alte prestazioni.
La soluzione commerciale Nvidia Tesla Accele-
rated Computing Platform (Fig. 4) è un ultimo
esempio di GPU di Nvidia per applicazioni in
HPC e data analisi. Offre performance quasi due
volte superiore e il doppio della larghezza di ban-
da della memoria del suo predecessore, l’accele-
ratore GPU Tesla K40. È dotata di 24 GB di me-
moria GDDR5 ultra-veloce, 480GB/s di memory
bandwidth e 4.992 CUDA parallel processing
core per accelerare le applicazioni. Tecniche di
power management, quali Dynamic Nvidia GPU
Boost Technology, aiutano a scalare in modo di-
namico il clock delle GPU per massimizzare le
prestazioni.
I maggiori prodotti di FPGA sono
Alterae
Xilinxche controllano circa l’80% del mercato con altre
aziende, quali Lattice, che detengono una quota
molto inferiore. Le FPGA della famiglia Cyclo-
ne V di Altera, grazie all’abbinamento tra logica
programmabile e processori dual-core Cortex-A9
di
ARM, hanno consentito ampio utilizzo soprat-
tutto in ambito automotive. Ultimamente la case
automobilistica Audi ha deciso di adottare que-
ste soluzioni per i sistemi ADAS (Advanced Dri-
ver Assistance System).
La famiglia di Altera integra una grande varie-
tà di interfacce che consentono di ridurre i tempi
complessivi di progettazione. I dispositivi sono re-
alizzati con il processo 28 nm Low-Power (28LP)
di TSMC che offre un buon power management e
riduce i relativi costi di gestione (Fig. 5).
Il mercato in evoluzione, quali scenari
I progressi nella tecnologia FPGA hanno permes-
so la realizzazione di una più potente classe di
processori, riconfigurabili con interfacce ad alta
velocità che alla fine potrebbe sostituire i server
general-purpose per carichi di lavoro specifici.
Fig. 4 - GPU Nvidia
Modello Tesla K8